
It’s a common Email-to-Case complaint. If a customer creates an email with multiple service email addresses (in other words, multiple email addresses that forward to email-to-case), multiple cases are created. Traditional resolutions fall into two categories.
- One email service address per org. I.e. Never create more than one email service address. This is a simple and effective solution. With only one email service address, multiple cases will be reduced. The solution, however, limits the intended Email-to-Case functionality.
- Dedupe cases. The concept is basic enough. Allow Email-to-Case to create duplicates. Then resolve these duplicates after the fact via automated and/or manual case merge. While it sounds simple enough, this is not always a straight-forward process. In addition, allowing the creation of cases means automation, assignment rules, automated responses, etc. have already fired. This can have a direct impact on productivity and ticket times.
Is there another option?
Absolutely. With the help of Email-to-Flow, duplicates can be removed during the ingestion process.
Interesting. Tell me more.
Let’s look at a simplified example. A company has two Email-to-Case email addresses defined. One email is intended to provide support for Product A (which we will refer to as “priority”). Another email is intended to provide support for Product B (which we will refer to as “secondary”). A customer is unable to determine which product they are using, so they decide to send email to both email service address.

Seems logical. What’s wrong with that?
From a customer experience, this indeed makes sense. The customer most likely assumes that a single case will be created and reviewed by both teams (eventually being routed appropriately). The problem is that standard Email-to-Case processes each email address referenced in the email as a unique transaction. In other words, the Email-to-Case process is kicked off for the priority email address and again for the secondary email process. The result? Two unrelated cases.
Oye… that stinks. How can Email-to-Flow help?
Since Email-to-Flow exposes email services in flow, Email-to-Flow can identify the duplicate before the duplicate case is created. In this example, we will simply ignore the duplicate email service call (and, therefore, not create a duplicate case).
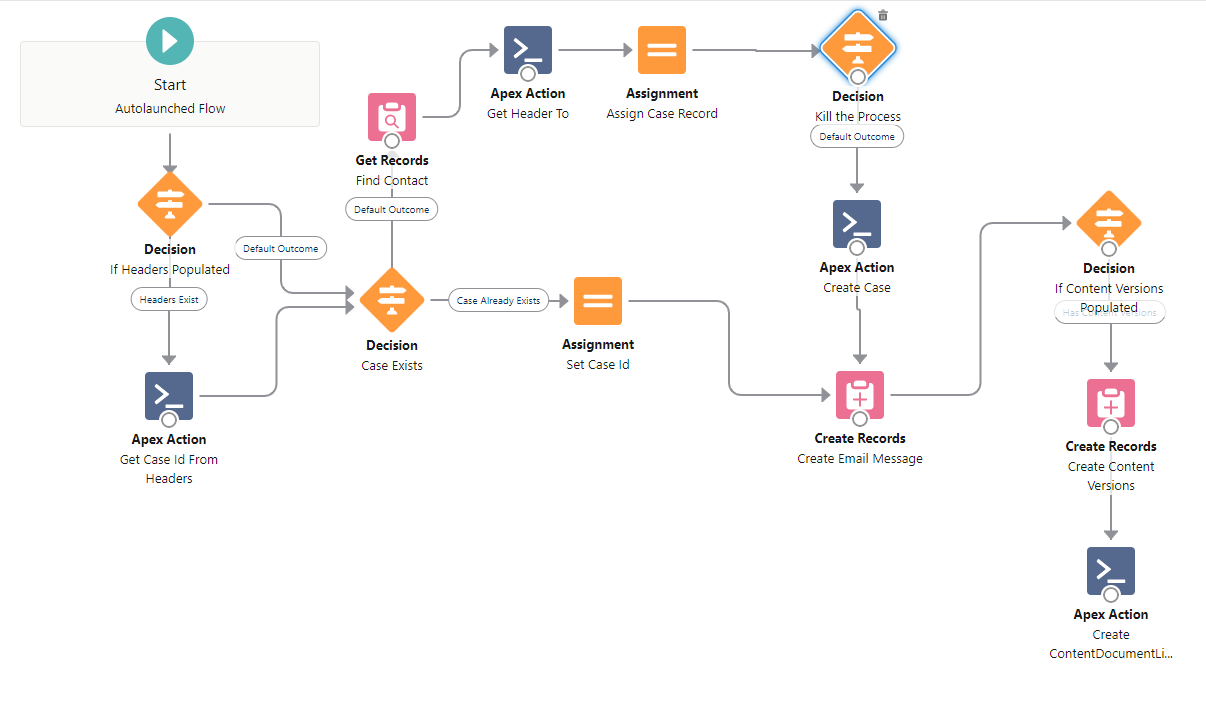
First, we clone the out of the box template. (Note: In this scenario, we are creating and mapping the flow to the secondary email address).
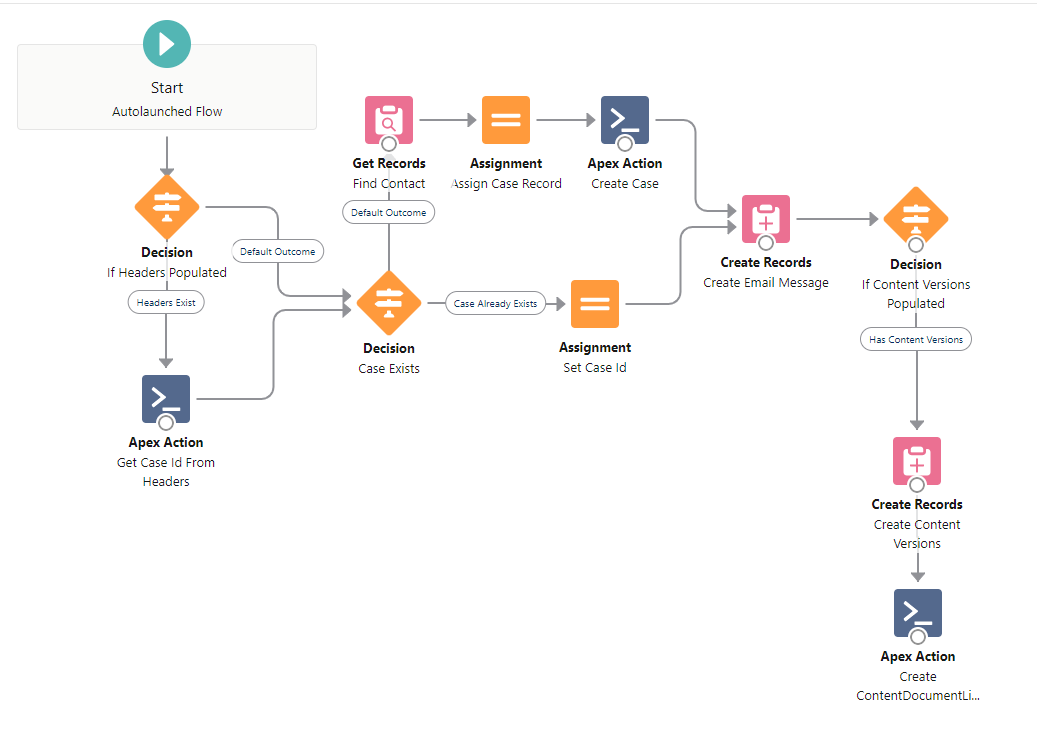
Next, we add the Email-to-Flow Get Header Value apex action. In this instance we are interested in the header value “To”. The “To” value will store the emails original to email addresses.
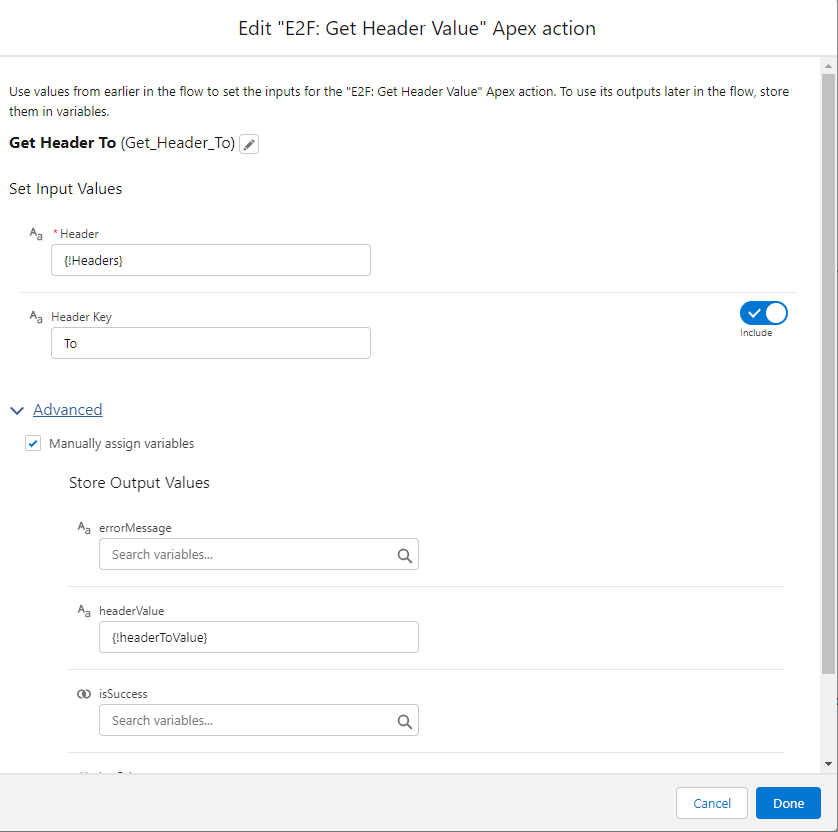
Next, we add a decision block. Since this flow is running for the secondary email address, we are interested to know if the “To” header value also included the priority email address.
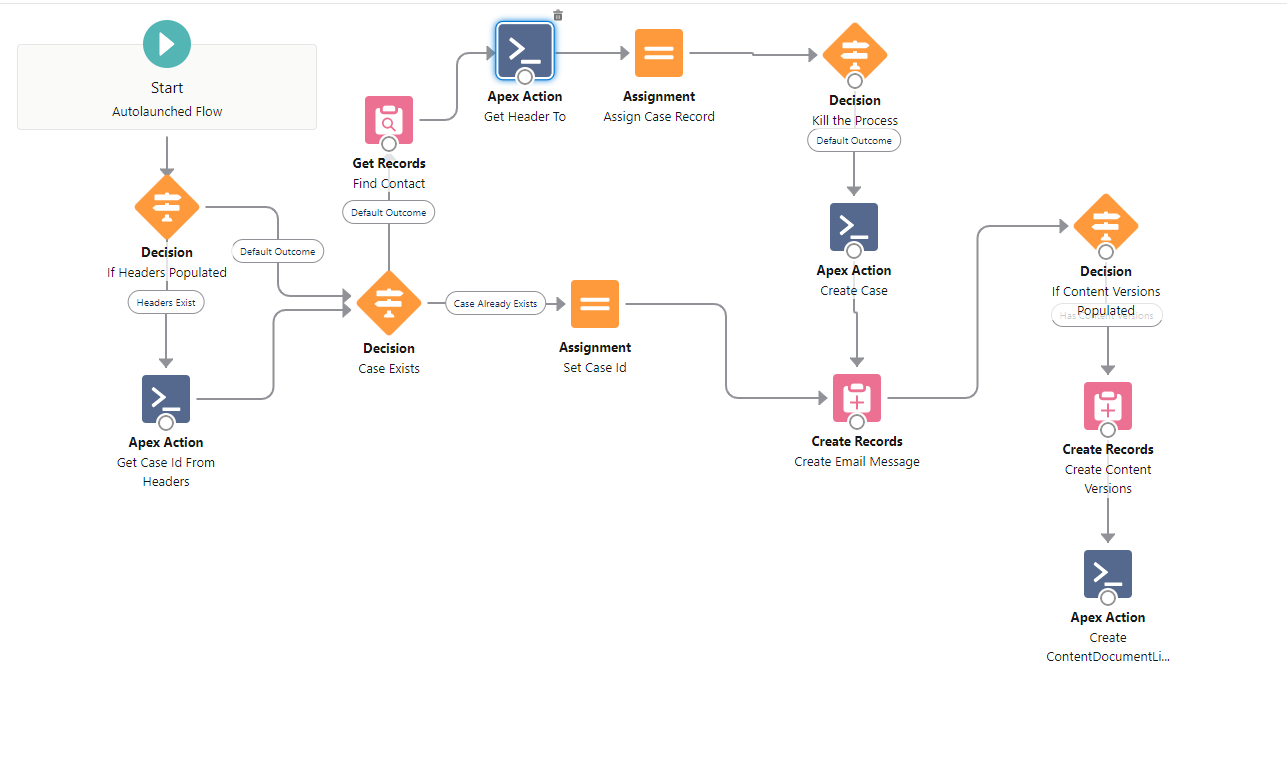
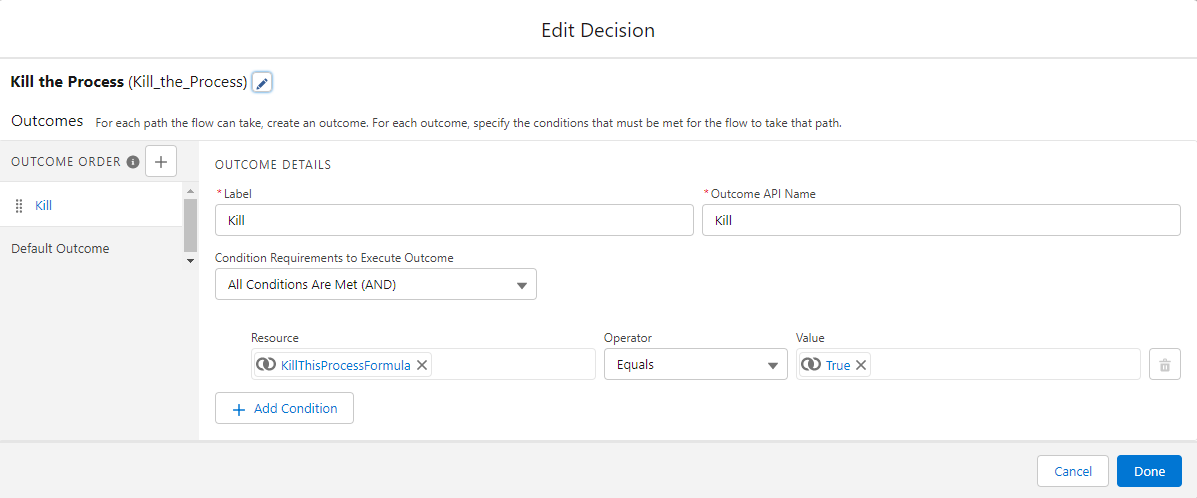
If the priority email address exists, we set KillThisProcess to true.
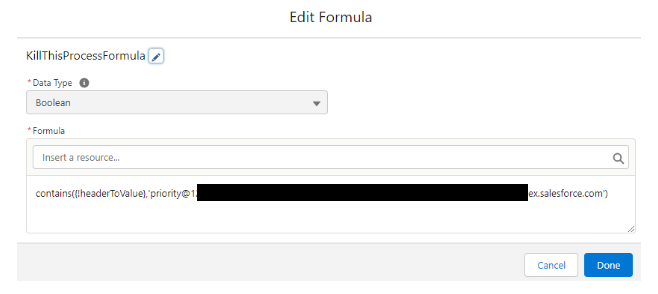
Finally, if KillThisProcess is set to true, the flow simply ends.
That’s awesome! Can I add additional logic as well?
Of course! This is Email-to-Flow. You can extend the functionality to meet your needs.